GIT基础知识
什么是git?
分布式版本控制系统,它是由Linux(全球比较大的服务器系统)创始人花两周使用C语言编写的,(在GIT命令窗口中一般是执行Linux命令)
什么是版本控制系统?
能够把之前操作的具体信息记录下来,方便日后的更改。
- 备份文件
- 记录历史
- 回到过去
- 多端共享
- 团队协作
常用的版本控制系统
- git:分布式版本控制系统
- svn:集中式版本控制系统
面试题:分布式和集中式的区别?
[集中式]:
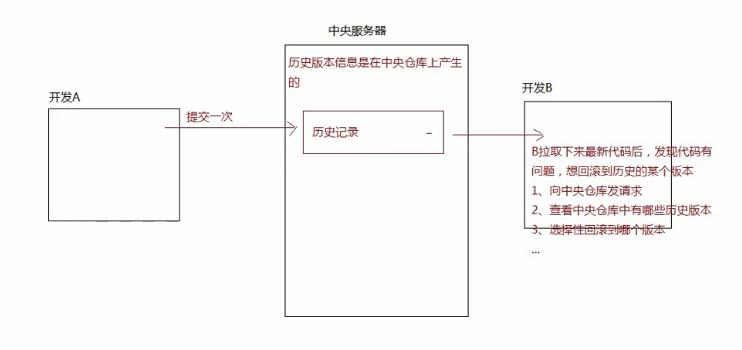
- 想要做历史记录的查看或者备份,必须连接到中央服务器才可以(需要联网)
- 处理速度没有git快
[分布式]:
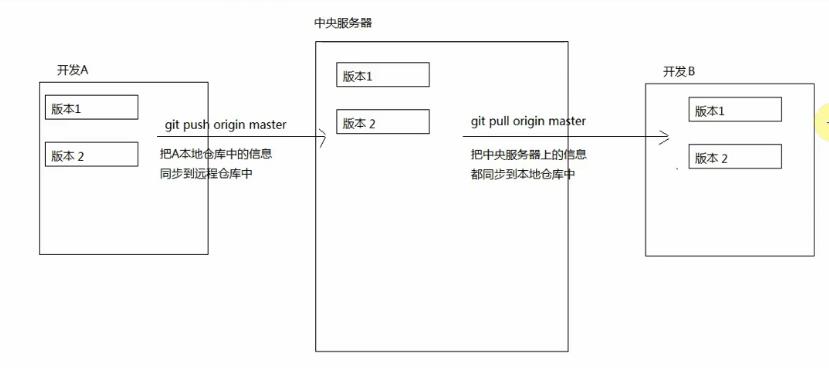
- 每个开发者本地都是一个单独的仓库,在自己的仓库中就可以完成历史版本记录和查看(不需要联网)
- git处理的速度更快(git是按照数据存储的)
Linux操作系统中常用的命令
ls:查看当前目录下的文件(或文件夹)
-l :查看详细信息
-a:查看隐藏文件
-la:同时具备以上特点
- clear:清屏
cd: 目录切换
- cd ../ 返回上级目录
- cd ./ 返回当前目录
- cd / 返回根目录
- cd xxx 进入到指定文件夹
- cd E 进入到指定的磁盘
mkdir 创建文件夹
touch 创建一个空文件
- 可以创建无文件名的文件,例如:
touch .gitignore - 在电脑隐藏文件后缀名的情况下,我们也不至于创建出1.txt.txt这样重复后缀名的文件
- 可以创建无文件名的文件,例如:
vi 向指定文件中插入内容 例如:vi.txt
- 首先进入命令窗口模式
- 我们先按i,进入到插入内容模式
- 编辑需要写的内容
- 按ESC键,再按英文下的 : 键,再按wq(保存并退出)
- 按 q!(强制退出,新输入的内容不保存)
echo xxx > 1.txt 把xxx内容放到1.txt文件中,如果没有这个文件则创建这个文件(新存放的内容会替换原有文件的内容)
- echo xxx >> 1.txt 新的内容会追加到原有内容的后面
- cat 查看文件中的内容
- cp 拷贝文件
- rm 删除文件
- -r 递归删除(把当前文件夹中所有的后代元素都遍历到删除)
- -f 强制删除
- -rf 上面两种合并到一起,没有办法还原回来,使用要慎重
Git的工作原理和流程
安装完成git后,我们应该先把基础信息配置一下(自己需要配置一次即可)
2
3
4
5
6
> $ git config --global user.name xxx
> $ git config --global user.email xxx
> (xxx写github/coding等平台的账号和邮箱)
>
>
Git的工作流程
Git是分布式版本控制系统,每一台客户端都是一个独立的git仓库(有git工作的全套机制)
一个git仓库分为三个区域;
- 工作区:平时写代码的地方
- 暂存区:写好的一些代码暂时存储的地方
- 历史区:生成一个个版本记录得地方
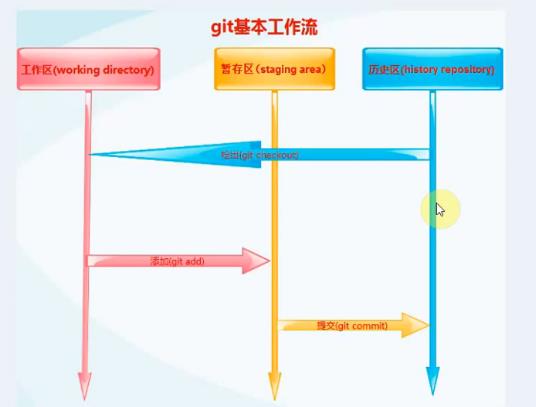
1.创建GIT仓库
在指定目录中,打开git bash命令行,执行
git init,相当于以当前目录作为基础,创建了一个本地git仓库创建完成后,会在项目的根目录中展示 .git 这个隐藏文件:有这个.git文件的才叫做git仓库,没有则不能被称为git仓库(因为暂存区和历史区都是存在 .git 文件夹中的)
2.把工作区的内容提交到暂存区
2
3
4
5
6
7
8
9
10
> $ git add . 把所有修改的文件(修改和新增的包含,删除的不包含)提交到暂存区
> $ git add -u 把所有修改的文件(包含修改和删除的,不包含新增的)
> $ git add -A 是点和u的集合体,(所有修改,新增,删除的信息都会提交到暂存区),但是真实效果中两者都差不多,用哪个都可以
>
>
> $ git status 查看当前文件的状态
> 红色:在工作区中,还没有提交到暂存区
> 绿色:在暂存区中,还没有提交到历史区
>
如果在提交的时候,有些内容不想提交,我们可以增加git提交的忽略文件:
.gitignore(没有文件名只有后缀名).gitignore 中的信息:
.idea // 使用WS打开项目或者编辑项目,自动会生成的文件
node_modules // 使用npm安装模块的时候,当前安装在项目中的第三方模块都在这个文件夹中(之所以忽略是因为文件太大了)
.DS_Store (mac本中的文件)等等
3.把暂存区提交到历史区
1 | $ git commit |
【root-commit】根提交:
- 简单理解为:第一次提交到历史区域,如果我们创建一个新的仓库。但是没有做根提交,此时我们仓库中没有任何分支(哪怕是master),也就不存在所谓的分支切换(当前仓库还不完整,只有一个工作流程走完一遍才算完整)
4.工作流中的一些细节知识:
不管是从工作区提交到暂存区,还是从暂存区提交到历史区,每一个区域当前的内容是已知保存下来的不会消失。
1 | $ git log |
都是查看历史提交记录的(也相当于查看历史版本号),在没有历史版本回滚的时候,我们用哪个都可以。如果有历史版本回滚,
git log只能查看当前回退版本以前的版本
1 | $ git rm --cached . -r |
可以把
.替换为具体的文件名,这条命令的意思是:从暂存区把所有内容(或者是你指定的具体文件)都撤回到工作区(不管暂存区中的内容是否已经提交到历史版本上了,也不管是你第几次放到暂存区的,统统撤回到工作区)
这种方式太暴力,我们用的很少,不推荐使用
1 | $ git checkout . |
这条命令的意思是:
把暂存区内容撤回工作去(覆盖现有工作区中的内容无法找回)。
也可以理解为:用上一个暂存区存储的内容覆盖现有工作区的内容,工作区内容变为和上一个暂存区一样的内容,暂存区内容还在。
存在问题:只能限制当前代码还没有提交的情况,当前代码没提交回滚的是上一次提交到暂存区的内容(和工作区内容不一样);如果当前这次也提交了,暂存区和工作区一样,回滚回来也是一样的,这个方式就解决不了了。
解决问题:
- 输入命令
$ git reset HEAD .: 在暂存区中,回滚到上一次暂存区中记录的内容(暂存区先回滚一次)- 输入命令
$ git checkout .: 把最新暂存区的内容回滚到工作区,替换工作区中的内容
1 | $ git diff |
工作区 VS 暂存区 :
git diff工作区 VS 历史区 :
git diff master暂存区 VS 历史区 :
git diff --cached查看不同区域之间代码的不同,我们一般都是基于可视化的页面来查看不一样的
最重要的代码回滚技巧:
1 | $ git reset --hard 版本号 |
git log可以查看版本号回滚的时候指定的版本号不一定非常全,有七八位即可
当我们回滚到某一个历史版本之后,暂存区和工作区的内容都将被这个版本内容所代替
1 | $ history > xxx.txt //(把历史操作步骤输出) |
团队协作开发下的git操作
- 前面讲的都是单独开发,在自己本地建立git仓库的一系列操作流程,在团队写作开发下,流程还是有所区别的
1. 创建中央仓库
一般是由团队技术LEADER或者指派人完成的,仓库中默认是有一些初始化文件的
中央仓库可能是在:gitHub,Coding,自己公司的git仓库服务平台,自己公司的服务器等…
基于gitHub创建远程仓库,创建完成后会生成一个远程地址,例如:
https//github.com/username/Repository name.git作为LEADER,还需要把项目中一些基础的信息提交到远程仓库上:
- 在自己本地创建一个仓库,把一些基础内容都放在仓库中
- 把新增加的内容提交到本地仓库历史区中
- 让本地仓库和远程仓库保持关联
- 把本地仓库历史区中的信息同步(推送)到远程仓库上
让本地仓库和远程仓库保持关联:
2
3
4
5
6
7
>
> $ git remote rm 名字 // 移除关联
>
> $ git remote -v // 查看当前仓库和哪些远程仓库保持关联
>
>
让本地历史区信息和远程仓库信息保持同步:
第一种方法:
2
3
4
5
6
7
8
> // 把本地信息推送到远程仓库上
>
> $ git pull origin master
> // 把远程的拉取到本地仓库
>
> (origin 是本地和远程仓库关联的那个名字,master 是远程仓库的主分支)
>
第二种方法:(推荐使用)
我们创建完成后远程仓库后,可以直接通过
git clone 仓库地址 仓库别名(可以不写)的方式把远程仓库克隆到本地:相当于在本地创建了一个仓库
也让本地这个仓库和远程仓库保持了连接(名字:origin)
也把远程仓库现有的内容克隆到了本地
2. 无分支模式下的团队协作
作为开发者每天来的第一件事情或者提交代码之前,都要先pull一下
- 【如果远程仓库和本地仓库不是同一个文件同一行代码冲突】
git 会自动依赖于 Fast-forward 模式进行合并
自动合并后,我们重新提交即可
git add/commit/push
【同一个文件的同一行代码冲突】
找到冲突的文件,留下自己想要的代码
不管之前是否commit过,都要重新的commit,然后push即可
2.单独分支管理
每天第一件事情,就是创建一个dev分支并切换到这个分支上
正常的开发代码,把每天开发的任务都先提交到自己的分支上
提交到远程仓库上:
把本地自己分支DEV中的内容,合并到本地自己的MASTER 分支下
把自己本地创建的分支删除(可以不删除,但是有的公司不希望远程中出现分支,或者避免开发人员的分支冲突,提交之前都要把自己创建的分支删除掉)
和第一种只使用MASTER分支一样了,把本地最新合并的MASTER分支代码,提交到远程仓库的MADTER下,(冲突合并即可)
操作分支的基础命令:
2
3
4
5
6
7
8
> $ git branch xxx //创建一个新的分支(当切换到某个分支上的时候,会把当前MASTER分支中的新信息同步到这个分支上)
> $ git checkout xxx //切换到某个分支上
> $ git checkout -b xxx //创建一个新的分支并且切换到这个分支上
> $ git branch -D xxx //删除某个分支(一定要切换到其他分支上才可以删除当前分支)
> $ git merge xxx //合并分支内容
> $ git log --graph / --oneline //再有分支的情况下,可以更清楚地查看分支的提交和合并内容(了解就好)
>
GitHub界面操作
给别的仓库提交代码修改或建议
首先fork别人的仓库
- 把别人的仓库克隆一份一模一样的,放到自己的账号下,变为自己的仓库(我们平时可以修改自己仓库的源码)
- fork的仓库和别人的原始的仓库会默认建立一些关系,我们可以把自己仓库中和别人不一样的地方,提交给别人,用(pull-request)
把自己fork的仓库,克隆到本地
- 以后自己有一些新的代码心得,可以自己尝试去修改,然后同步到自己fork的仓库中
- 在github中点击 new pull request
GitHub还可以发布非后台项目
GitHub只提供了web站点的发布,后台项目没有提供必要的环境
把整个仓库作为一个项目发布(这种模式不常用)
master是项目代码,gh-pages分支下存储的是项目预览页面的代码
其他人克隆研究的是master分支下的代码
看介绍页面,看的是gh-pages分支下的代码
- 创建一个仓库
- 把仓库克隆到本地
- 把源码传到master分支上
- 在本地仓库中创建gh-pages分支
- 把介绍页面放在gh-pages分支下
- 把介绍页面的内容上传到github的gh-pages分之下
访问页面:http://用户名.github.io/仓库名/页面名.html (如果页面是index可以忽略不写)
把自己写的纯静态页面项目通过github地址可以看到页面效果
第一步,在github上新建一个仓库,把远程仓库通过
git clone xxx克隆到本地第二步,把自己写好的作品放在本地仓库中
第三步,通过
git add -A,git commit -m,git push origin master三步操作,把自己的项目同步到远程仓库github中
- 以后修改后,重新执行这三步推送即可
在投简历的时候,把网址
https://用户名.github.io/仓库名写到简历上就可以访问到页面效果。如果觉得地址太长不好记,也可以通过草料二维码 ,来制作自己喜欢的二维码


